
I am a first-year Ph.D. student in Computer Science at Georgia Tech.
Previously, I was a research assistant at the Data-Driven Decision Intelligence (D3I) Lab at William & Mary (2025–2026). I received my M.S. degree in Electrical and Computer Engineering from UCLA (2023–2025), where I was a member of the Wireless Lab at UCLA, supervised by Prof. Ian P. Roberts. Before that, I obtained my B.Eng. in Communication Engineering from Chongqing University (2019–2023).
My research focuses on reinforcement learning, generative models, and large language models. I am currently especially interested in diffusion language models, with a focus on better understanding their behavior, limitations, and inference mechanisms. My work spans both discrete and continuous diffusion language models, with the goal of improving their inference efficiency and generation quality. Previously, I worked on wireless communications, and I remain interested in opportunities to apply AI methods in this domain.
Feel free to contact me if you are interested in further discussion or potential collaboration.
Projects
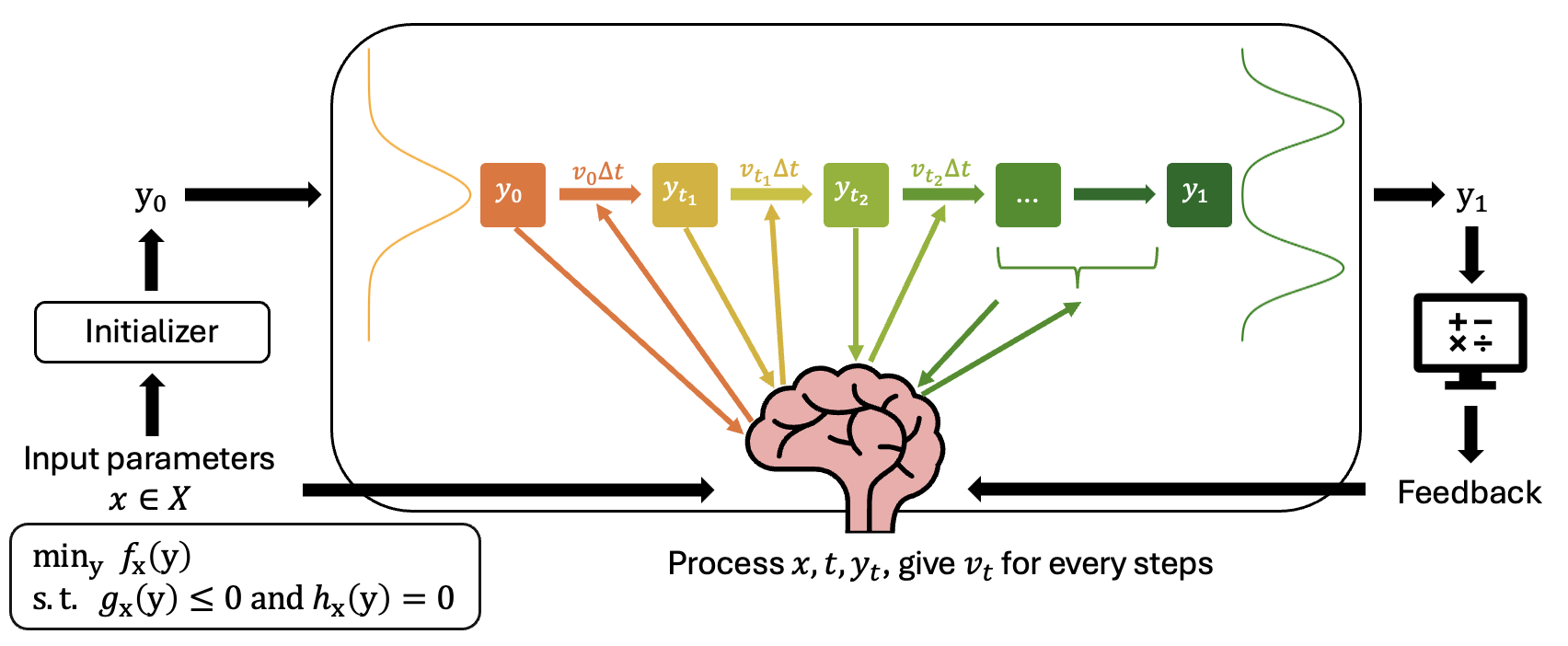
Solving Constrained Optimization Problems as ODE-based Models Using Reinforcement Learning
Han Meng, Xinsong Feng, Yang Li, Chenan Wang, Kishansingh Rajput, Malachi Schram, Haipeng Chen
TMLR, 2026
We propose CMFO (Constrained Markov Flow Optimizer), which unifies flow-matching generative models and reinforcement learning to solve constrained optimization problems with improved efficiency and feasibility.
Previous learning-to-optimize (L2O) methods on constrained optimization problems often treat neural networks as initializers that generate approximate solutions requiring substantial post-hoc refinements. This approach overlooks a key insight: Solving complex optimization problems often requires iterative refinement of candidate solutions, a process naturally aligned with the Markov Decision Process (MDP) and reinforcement learning (RL) framework. We show that within the MDP framework, RL and Ordinary Differential Equation (ODE)-based generative models (e.g., diffusion, flow matching) are formally equivalent, unifying them as trainable optimizers. Building on our unified perspective, we propose to train a flow-matching model within an RL paradigm as a learnable refinement mechanism, thereby incorporating constraint satisfaction directly into the optimization process. To further enhance feasibility, we introduce a minimal correction step that adjusts solutions to ensure constraint compliance. Empirical results demonstrate that our approach achieves state-of-the-art performance across a range of constrained optimization tasks, yielding improvements in efficiency, solution quality, and feasibility over prior baselines.

Offline Reinforcement Learning with Generative Trajectory Policies
Xinsong Feng, Leshu Tang, Chenan Wang, Haipeng Chen
ICML 2026
We propose Generative Trajectory Policies (GTPs), an ODE-based framework that unifies generative policies in offline RL, overcoming the performance–efficiency trade-off and achieving state-of-the-art results on D4RL benchmarks.
Generative models have emerged as a powerful class of policies for offline reinforcement learning (RL) due to their ability to capture complex, multi-modal behaviors. However, existing methods face a stark trade-off: slow, iterative models like diffusion policies are computationally expensive, while fast, single-step models like consistency policies often suffer from degraded performance. In this paper, we demonstrate that it is possible to bridge this gap. The key to moving beyond the limitations of individual methods, we argue, lies in a unifying perspective that views modern generative models—including diffusion, flow matching, and consistency models—as specific instances of learning a continuous-time generative trajectory governed by an Ordinary Differential Equation (ODE). This principled foundation provides a clearer design space for generative policies in RL and allows us to propose Generative Trajectory Policies (GTPs), a new and more general policy paradigm that learns the entire solution map of the underlying ODE. To make this paradigm practical for offline RL, we further introduce two key theoretically principled adaptations. Empirical results demonstrate that GTP achieves state-of-the-art performance on D4RL benchmarks — it significantly outperforms prior generative policies, achieving perfect scores on several notoriously hard AntMaze tasks.

Sequential stochastic combinatorial optimization using hierarchal reinforcement learning
Xinsong Feng, Zihan Yu, Yanhai Xiong, Haipeng Chen
ICLR 2025
We propose Wake-Sleep Option (WS-option), a hierarchical reinforcement learning framework for sequential stochastic combinatorial optimization that jointly optimizes budget allocation and node selection in a two-layer MDP.
Reinforcement learning (RL) has emerged as a promising tool for combinatorial optimization (CO) problems due to its ability to learn fast, effective, and generalizable solutions. Nonetheless, existing works mostly focus on one-shot deterministic CO, while sequential stochastic CO (SSCO) has rarely been studied despite its broad applications such as adaptive influence maximization (IM) and infectious disease intervention. In this paper, we study the SSCO problem where we first decide the budget (e.g., number of seed nodes in adaptive IM) allocation for all time steps, and then select a set of nodes for each time step. The few existing studies on SSCO simplify the problems by assuming a uniformly distributed budget allocation over the time horizon, yielding suboptimal solutions. We propose a generic hierarchical RL (HRL) framework called wake-sleep option (WS-option), a two-layer option-based framework that simultaneously decides adaptive budget allocation on the higher layer and node selection on the lower layer. WS-option starts with a coherent formulation of the two-layer Markov decision processes (MDPs), capturing the interdependencies between the two layers of decisions. Building on this, WS-option employs several innovative designs to balance the model’s training stability and computational efficiency, preventing the vicious cyclic interference issue between the two layers. Empirical results show that WS-option exhibits significantly improved effectiveness and generalizability compared to traditional methods. Moreover, the learned model can be generalized to larger graphs, which significantly reduces the overhead of computational resources.