Note for "Tutorial on Diffusion Models for Imaging and Vision"
1 Langevin Dynamics
[!NOTE]
How to sample from a distribution
The Langevin dynamics for sampling from a known distribution p(x) is an iterative procedure for t=1,…,T:
xt+1=xt+τ∇xlogp(xt)+2τz,z∼N(0,I),
where τ is the step size which users can control, and x0 is white noise.
Without the noise term, Langevin dynamics is gradient descent.
The intuition is that if we want to sample x from a distribution, certainly the “optimal” location for x is where p(x) is maximized (seeing the peak as a representation of a distribution). So the goal of sampling is equivalent to solving the optimization
x∗=xargmaxlogp(x).
distribution <=> peak <=> optimal solution
[!IMPORTANT]
Langevin dynamics is stochastic gradient descent.
We do stochastic gradient descent since we want to sample from a distribution, instead of solving the optimization problem.
2 (Stein’s) Score Function
The second component of the Langevin dynamics equation has a formal name known as the Stein’s score function, denoted by
sθ(x)=def∇xlogpθ(x).
The way to understand the score function is to remember that it is the gradient with respect to the data
x. For any high-dimensional distribution p(x), the gradient will give us vector field
∇xlogp(x)=a vector field=[∂x∂logp(x),∂y∂logp(x)]T
Geometric Interpretations of the Score Function:
The magnitude of the vectors are the strongest at places where the change of logp(x) is the biggest. Therefore, in regions where logp(x) is close to the peak will be mostly very weak gradient.
The vector field indicates how a data point should travel in the contour map.
In physics, the score function is equivalent to the “drift”. This name suggests how the diffusion particles
should flow to the lowest energy state.
3 Score Matching Techniques
Note that since the distribution is not known, we need some methods to approximate it.
Explicit Score-Matching
Suppose that we are given a dataset X={x1,…,xM}. The solution people came up with is to consider the classical kernel density estimation by defining a distribution
q(x)=M1m=1∑Mh1K(hx−xm),
where h is just some hyperparameter for the kernel function K(⋅), and xm is the m-th sample in the training set.
The sum of all these individual kernels gives us the overall kernel density estimate q(x).
The idea is similar to Gaussian Mixture Model.
Since q(x) is an approximation to p(x) which is never accessible, we can learn sθ(x) based on q(x). This leads to the following definition of the a loss function which can be used to train a network.
[!IMPORTANT]
The explicit score matching loss is
JESM(θ)=defEq(x)∥sθ(x)−∇xlogq(x)∥2
By substituting the kernel density estimation, we can show that the loss is
Once we train the network sθ, we can replace it in the Langevin dynamics equation to obtain the recursion:
xt+1=xt+τsθ(xt)+2τz.
Issue:
The kernel density estimation is a fairly poor non-parameter estimation of the true distribution.
When we have limited number of samples and the samples live in a high dimensional space, the kernel density estimation performance can be poor.
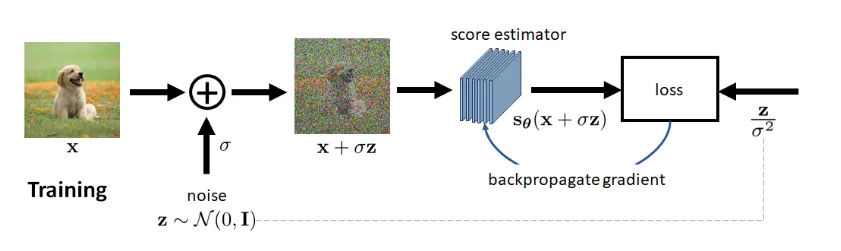
Denoising Score Matching
In DSM, the loss function is defined as follows.
JDSM(θ)=defEq(x,x′)[21∥sθ(x)−∇xq(x∣x′)∥2]
The idea comes from the Denoising Autoencoder approach of using pairs of clean and corrupted examples (x,x′). In the generative model, x′ can be seen as the xt.
The conditional distribution q(x∣x′) does not require an approximation. In the special case where q(x∣x′)=N(x∣x′,σ2), we can let x=x′+σz. This will give us