Offline Reinforcement Learning with Generative Trajectory Policies
Xinsong Feng, Leshu Tang, Chenan Wang, Haipeng Chen
ICML 2026

Overview
Offline RL needs policies that can model complex, multimodal behavior while staying fast enough for practical action generation. Existing generative policies tend to sit at opposite ends of this trade-off: diffusion policies are expressive but slow, while consistency-style policies are fast but can lose policy quality.
GTP resolves this by learning the full solution map of a continuous-time generative ODE. The result is a policy class that preserves trajectory information while enabling short, deterministic sampling paths at inference time.
Contributions
- A unified ODE view that connects diffusion, flow matching, consistency models, and consistency trajectory models as trajectory-learning policies.
- Generative Trajectory Policies, which learn the ODE solution map directly instead of choosing between slow iterative sampling and brittle one-step shortcuts.
- Two offline RL adaptations: stable score approximation for efficient supervision, and advantage-weighted generative training for value-guided policy improvement.
Highlights
Best average among the main offline RL baselines in the paper.
Large gain on sparse-reward, long-horizon navigation tasks.
Perfect normalized score in the full policy-improvement setting.
Short-horizon GTP keeps strong returns with lower latency.
Abstract
Generative models have emerged as a powerful class of policies for offline reinforcement learning (RL) due to their ability to capture complex, multi-modal behaviors. However, existing methods face a stark trade-off: slow, iterative models like diffusion policies are computationally expensive, while fast, single-step models like consistency policies often suffer from degraded performance. In this paper, we demonstrate that it is possible to bridge this gap. The key to moving beyond the limitations of individual methods, we argue, lies in a unifying perspective that views modern generative models—including diffusion, flow matching, and consistency models—as specific instances of learning a continuous-time generative trajectory governed by an Ordinary Differential Equation (ODE). This principled foundation provides a clearer design space for generative policies in RL and allows us to propose Generative Trajectory Policies (GTPs), a new and more general policy paradigm that learns the entire solution map of the underlying ODE. To make this paradigm practical for offline RL, we further introduce two key theoretically principled adaptations. Empirical results demonstrate that GTP achieves state-of-the-art performance on D4RL benchmarks — it significantly outperforms prior generative policies, achieving perfect scores on several notoriously hard AntMaze tasks.
Method
GTP is built around three choices: learn the trajectory map directly, stabilize supervision with a data-anchored score approximation, and guide the generative objective with critic advantages.
Learn a trajectory-level policy
GTP learns the ODE solution map itself. This lets the policy preserve trajectory information while still generating actions with only a few learned jumps.
Use score approximation for stable supervision
Training a full trajectory map from scratch can become self-referential and expensive. GTP avoids repeated inner-loop ODE solves by anchoring the training signal to offline data through a closed-form score surrogate.
Turn imitation into value-guided improvement
The actor still learns from dataset actions, but high-advantage actions receive larger generative weights. This keeps policy improvement data-supported instead of relying on unstable unconstrained Q maximization.
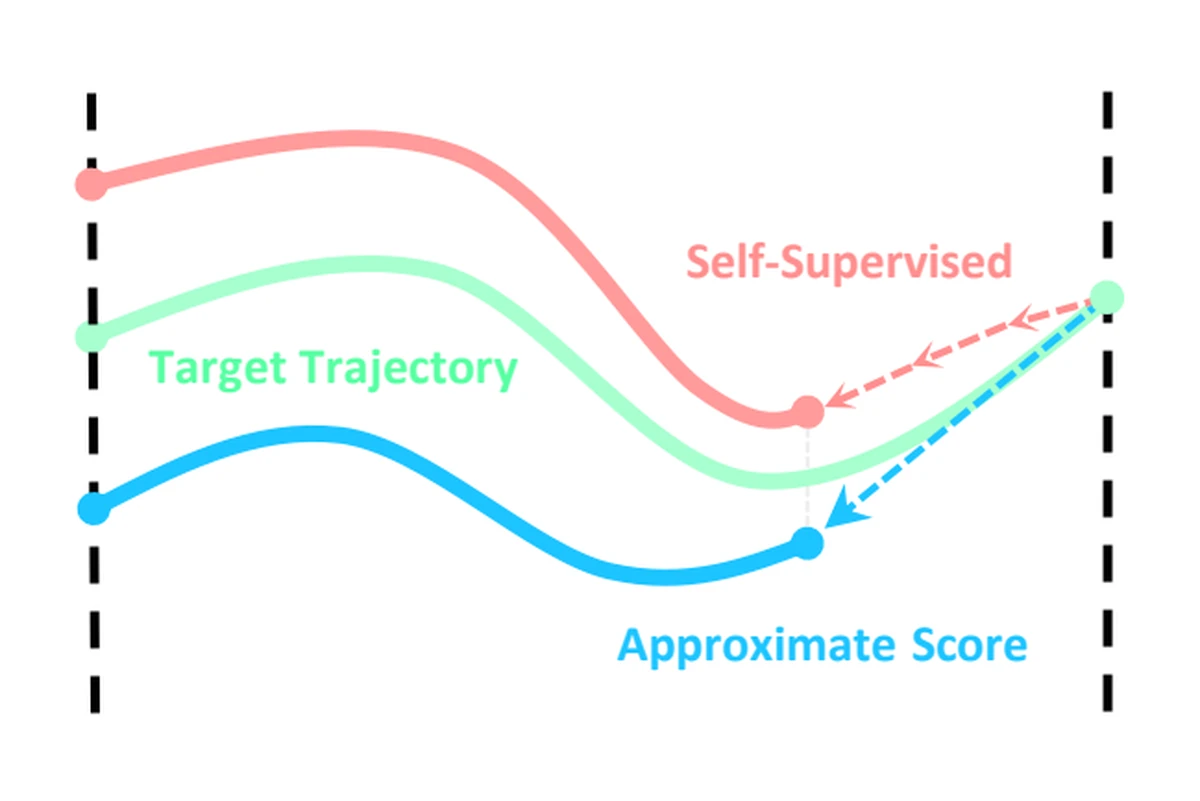
A data-anchored approximate score provides stable trajectory supervision without repeatedly solving the ODE.
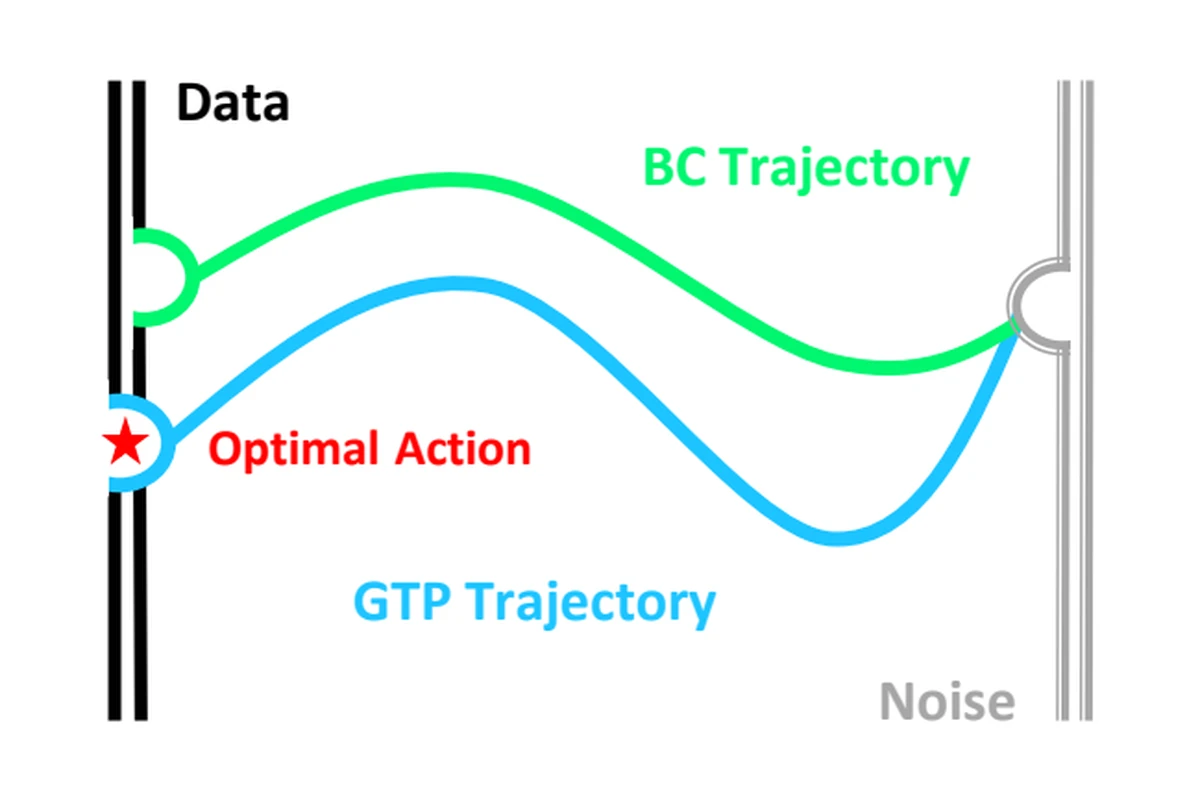
Advantage weighting shifts the learned trajectory toward higher-value actions while staying aligned with data.
Results
| Setting | GTP | Other Models | Takeaway |
|---|---|---|---|
| Behavior cloning | |||
| Gym | 82.3 | D-BC 76.3 C-BC 69.7 | Best average behavior-cloning policy across the locomotion suite. |
| AntMaze | 66.3 | D-BC 41.2 C-BC 44.1 | Much stronger imitation on multimodal, long-horizon datasets. |
| Policy improvement | |||
| Gym | 89.0 | D-QL 87.9 BDM 87.3 QGPO 86.6 | Highest average return in the main D4RL offline RL comparison. |
| AntMaze | 80.6 | QGPO 78.3 IDQL-A 79.1 D-QL 69.6 | Best average on the sparse-reward AntMaze suite. |
Scores are normalized D4RL averages reported in the paper. Full per-task results, ablations, and additional baselines are in the PDF.
Policy Visualization
A 2D multi-goal environment gives a qualitative view of policy expressiveness. The target dataset is multimodal, and the learned policy should preserve all goal-reaching modes rather than collapsing to a single direction.
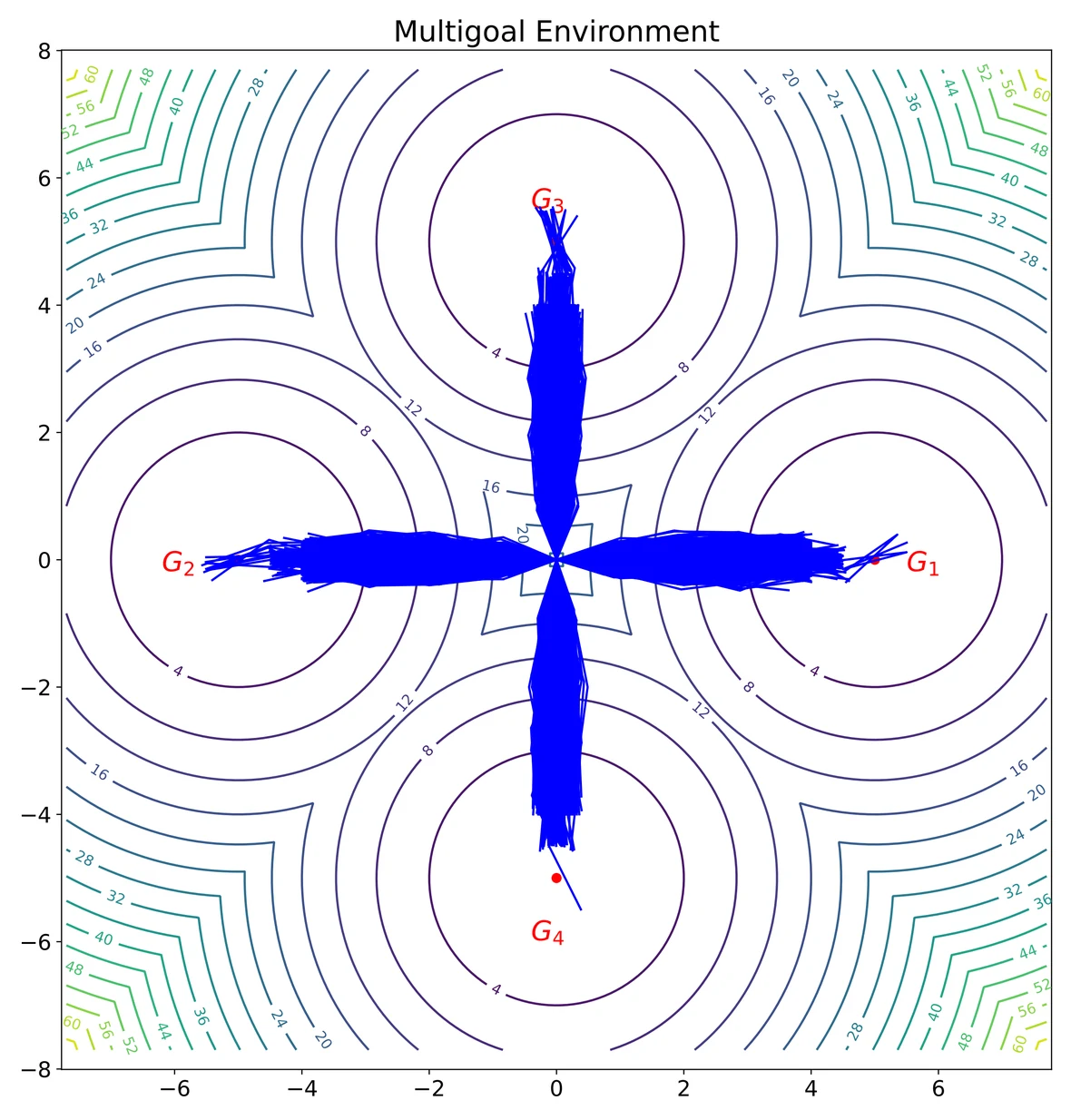
The behavior data contains four clear modes toward the four goals.
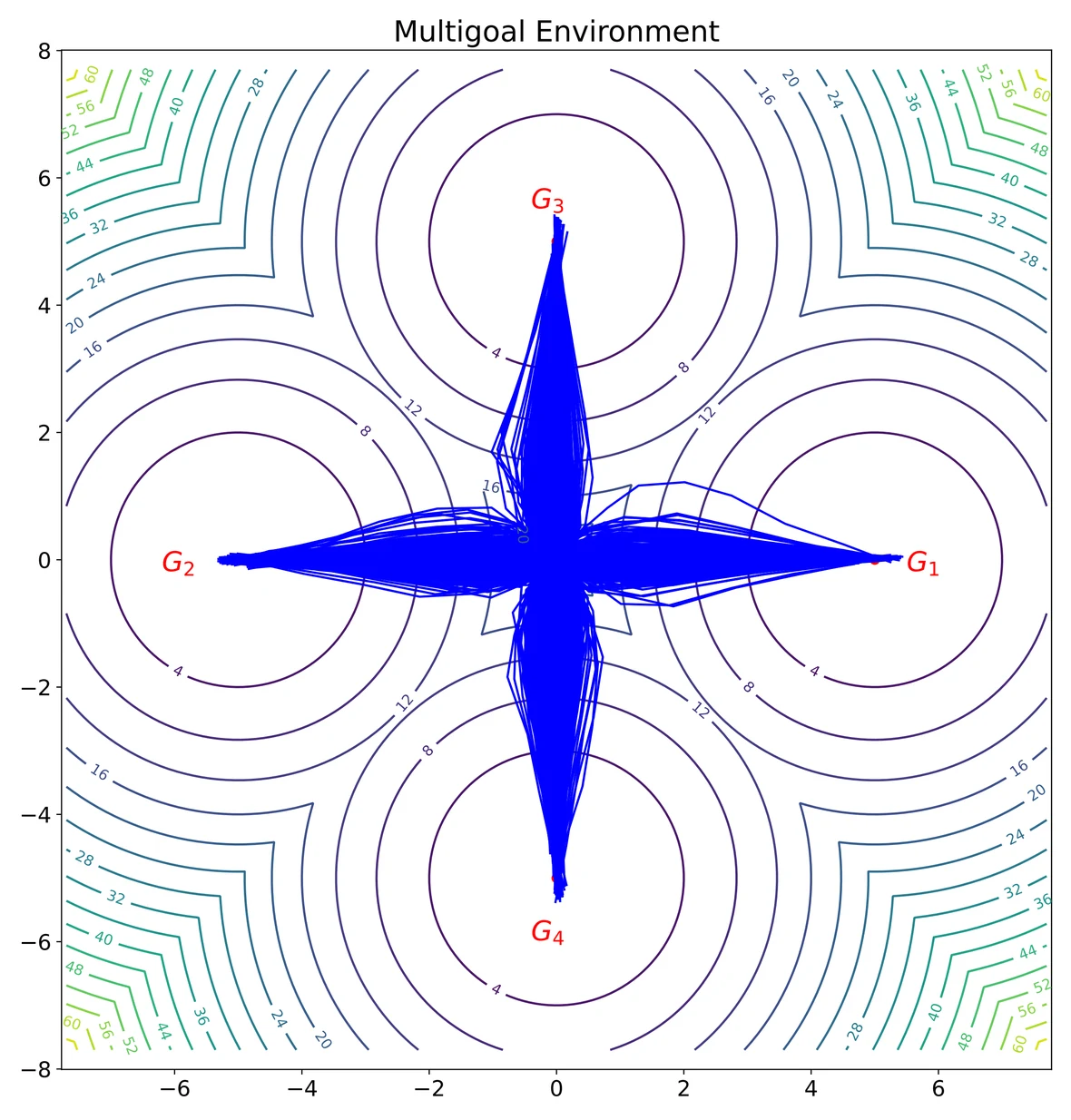
Diffusion-style sampling covers the modes, but trajectories are visibly noisy.
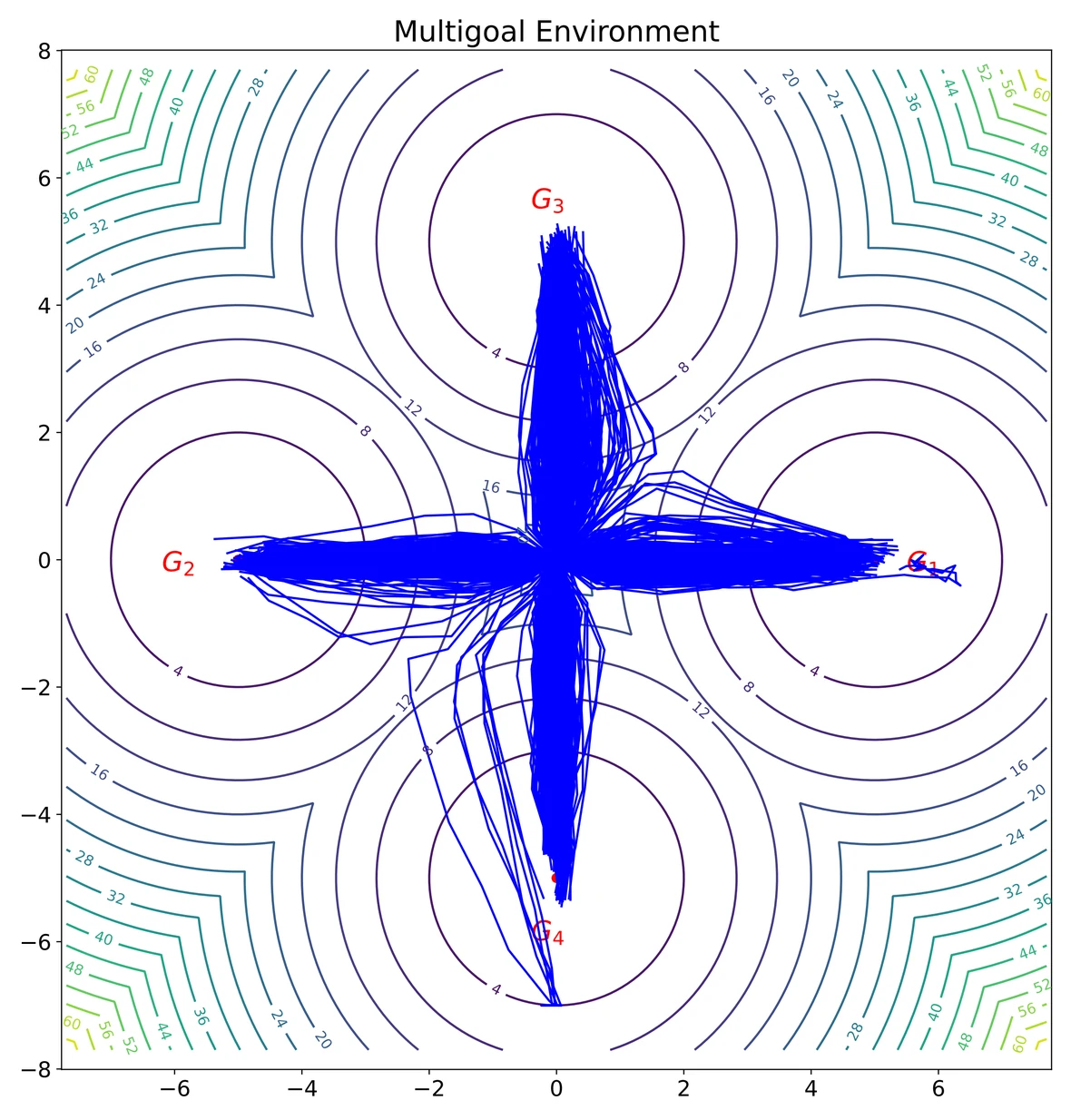
Fast consistency sampling can distort the multimodal structure.
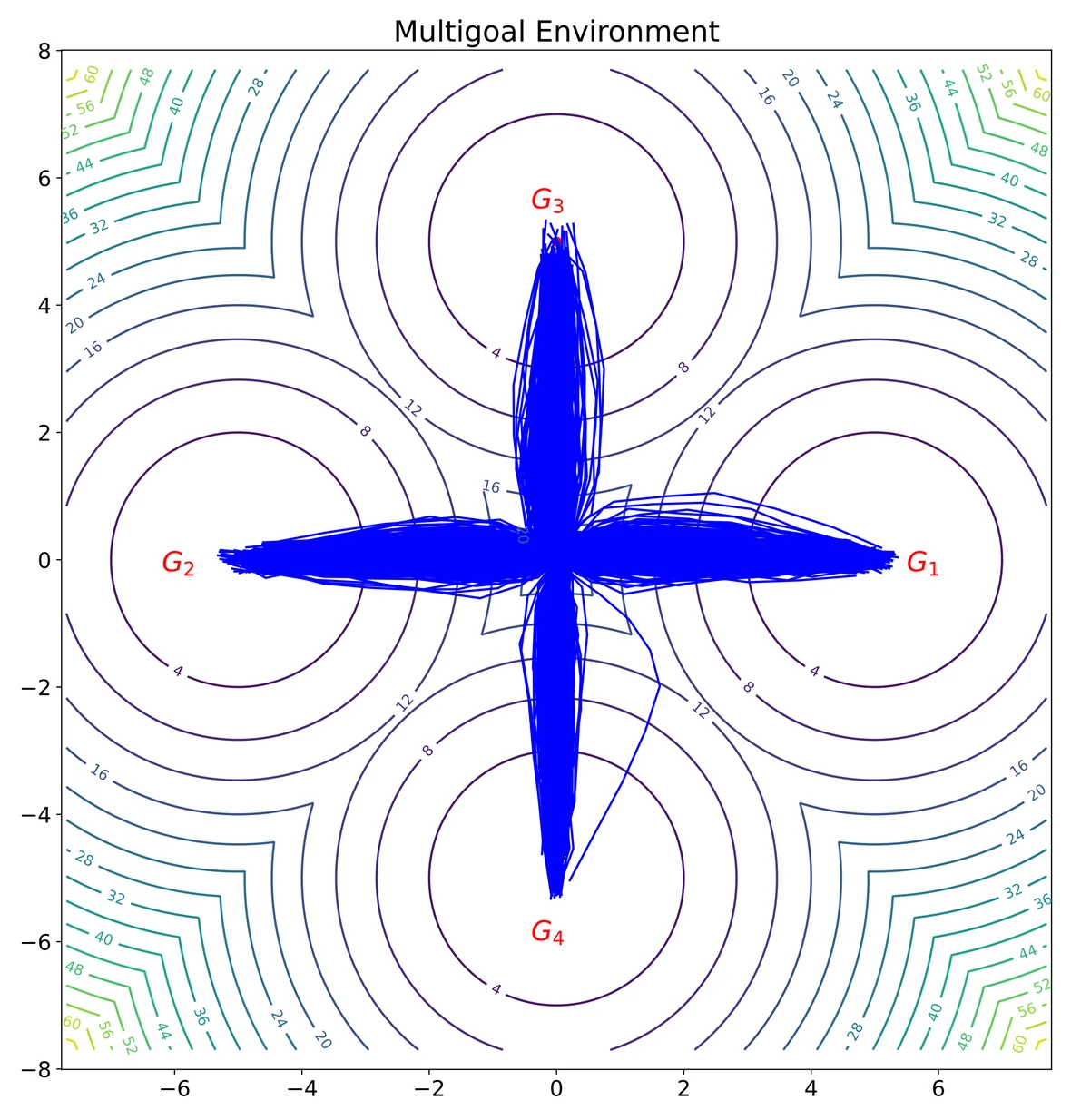
GTP preserves all four goal-reaching modes with compact trajectories.
The key point is mode preservation: in this toy environment, a strong generative policy should not collapse to one goal or smear probability mass across the space. GTP keeps the four-way structure while avoiding long iterative diffusion sampling.
Additional Evidence
Sampling steps
The two-step variant achieves a Gym average of 88.7 versus 89.0 for the five-step variant, showing that GTP does not rely on long ODE rollouts.
Compute profile
The K = 2 variant reports 3.8 hours of training and 0.67 ms inference, compared with 7.1 hours and 1.16 ms for Diffusion-QL under the matched setup.
Beyond D4RL
Additional OGBench and visual-observation experiments show that the same policy formulation can extend beyond low-dimensional state inputs.
Citation
@inproceedings{feng2026offline,
title = {Offline Reinforcement Learning with Generative Trajectory Policies},
author = {Feng, Xinsong and Tang, Leshu and Wang, Chenan and Chen, Haipeng},
booktitle = {International Conference on Machine Learning},
year = {2026}
}